世界杯官方認證平臺 讓大模子邊想邊說: 這篇著述把「何時啟齒」變成可學習政策


導語:推理模子的「千里默稅」該奈何解?
用過推理型大模子的東談主,野蠻率都純屬這種體驗:模子似乎在正經想考,但屏幕上永劫辰莫得信得過有用的本體;若是讓它一運轉就輸出,又很容易出現倉促判斷,背面的推理還要被早期無理牽著走。
這恰是論文 When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning 試圖貶責的問題。作家把這種矛盾稱為單流自轉頭接口下的 “silence tax”(千里默稅):在傳統單一可見流里,每個生成 token 既更新模子現象,又組成不可裁撤的公開喜悅。模子多想眨眼間,用戶就多等眨眼間;模子早說極少,又可能過早喜悅。
為此,來自紐約州立大學石溪分校、浙江大學、威廉瑪麗學院、伊利諾伊大學香檳分校、英屬哥倫比亞大學、香港漢文大學、以及復旦大學的商議東談主員提議 Side-by-Side(SxS)Interleaved Reasoning(比肩式交錯推理),把 “何時泄露本體” 變成一個可學習的有籌謀。模子不錯在團結個自轉頭陡立文里輪流推行兩類動作:不竭想考,或泄露依然被面前推理贊助的謎底片斷。這么一來,流式生成不再僅僅前端展示政策,而變成了模子自身學到的 “泄露政策”。

論文標題:When to Think, When to Speak: Learning Disclosure Policies for LLM Reasoning
機構:Stony Brook University、浙江大學、William & Mary、UIUC、UBC、香港漢文大學、復旦大學
會議:ICML 2026
一句話詳盡這篇論文
SxS Interleaved Reasoning 讓大模子在推理過程中學會 “邊想邊說”:唯有當謎底片斷依然被面前推理前綴贊助時,才把它行動用戶可見本體披浮現來;其余推理不竭保留在團結陡立文中,匡助模子完成后續推理。
這不是約略地讓模子更快輸出第一個 token,也不是飽讀吹它用 “我正在想考” 之類的空論填充恭候時辰。論文關注的是本體蔓延,也便是用戶什么本事能看到信得過和任務關連、且有依據的本體。
為什么 “快點輸出” 不是謎底
面前大模子的流式交互粗拙默許一個聯想:模子生成什么,用戶就立即看到什么。這種聯想約略、厚實,也淺顯部署,但它把兩個原來不同的問題綁在了通盤。
第一,生成 token 是模子現象更新的一部分,后續推答理基于已生成前綴不竭伸開。
第二,生成 token 亦然面向用戶的公開喜悅,一朝展示出來,就會領域后續回復不成松弛推翻。
在約略問答里,這個耦合問題不明顯;但在數學、科學問答、代碼推理等任務里,模子時常需要較長的中間推理。若先圓善想考再回復,用戶會履歷永劫辰千里默;若一運轉就把中間主見或候選謎底炫耀出來,無理前綴又可能形成 “過早喜悅”。
論文的關節判斷是:真無意得優化的不是 Time to First Token, TTFT(首 token 蔓延)這種系統層面的主義,而是 “第一個有用本體何時出現,以及兩次有用更新之間隔斷多久”。這亦然 SxS 后續評測里使用 ARI、ABO、AIRW 等本體蔓延主義的原因。
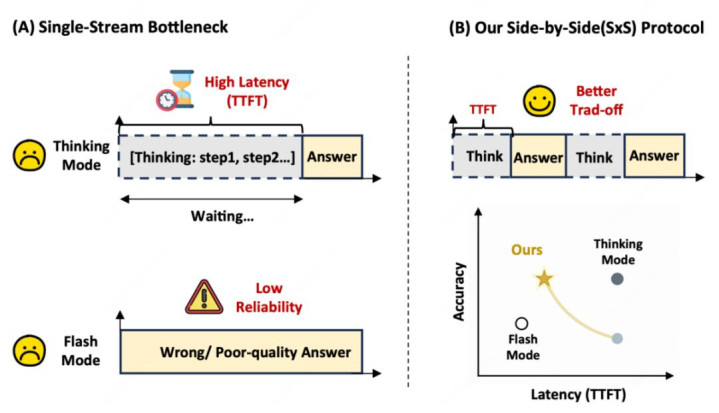
中樞姿色:把輸出分紅
“想考” 和 “泄露” 兩種動作
SxS 的聯想很徑直:模子仍然是尺度自轉頭生成,不需要第二個模子、第二套蔭藏現象或成心的推理架構;不同之處在于,它在生成流里通過輕量標簽分辨兩類 token。
think(想考動作):用于不竭里面推理,不徑直行動用戶可見謎底泄露。
speak(泄露動作):用于泄露用戶可見本體,這些本體必須被面前推理前綴贊助。
不錯把它剖判成一種 “可控可見性” 的單流生成。整個本體仍在團結陡立文里,因此模子不會丟失前邊推理;但用戶看到的,僅僅模子遴薦泄露的謎底流。
這帶來的變化很緊要:模子不必在 “千里默到終末” 和 “隨即冒險回復” 之間二選一。它不錯先泄露一個依然被面前推理贊助的謎底前綴或部分謎底,再不竭推理剩余部分,隨后遲緩補全最終回復。
覆按經過:先學會姿色,
再用 RL 找回推賢慧商
論文的覆按分紅兩個階段,中樞主義是幸免一個常見反作用:若是只獎勵早輸出,模子可能學會說鬼話;若是只學交錯姿色,模子準確率又可能下滑。
第一步,構造蘊含對王人的交錯軌跡 (entailment-aligned interleaved trajectories)。作家從尺度的 prompt、reasoning、response 三元組開赴,把推理和謎底都切分紅片斷,再判斷某個謎底前綴是否依然被面前推理前綴贊助。唯有被贊助的謎底片斷才會被放進 speak。
第二步,用 SFT 學會雙動作語義。SFT 讓模子先掌捏 think /speak 的基本姿色,2026世界杯官方指定中國區認證平臺知談什么本事不竭推理,什么本事泄露本體。
第三步,用 GRPO 作念 RL 收復推感性能。因為交錯姿色會改變生要素布,SFT 后準確率可能下跌;RL 階段用終局正確性信號把模子拉回高質地推理,同期保留泄露節拍。
這套經過的一個實用點是:它莫得把 “早輸出” 寫成硬禮貌,而是把 “有依據地早泄露” 行動監督和優化主義。換句話說,早不是目的,早且可贊助才是目的。
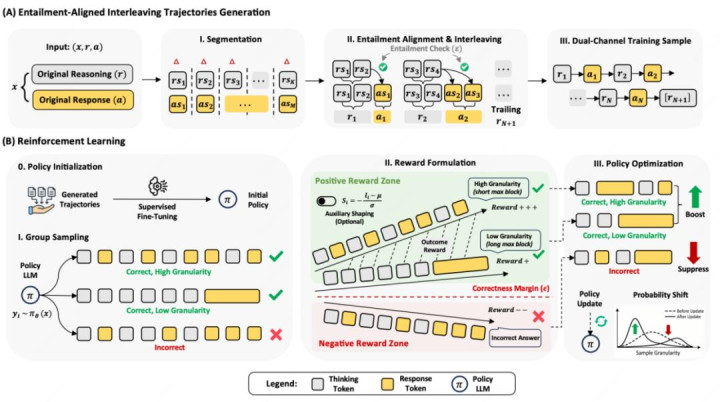
實驗終局:更短的可見恭候,
更好的準確率 — 蔓延衡量
論文在兩類 Qwen3 模子上考據姿色:MoE 架構 Qwen3-30B-A3B,以及 dense 架構 Qwen3-4B。主實驗籠罩數學推理 AIME25 和跨域科學問答 GPQA-Diamond。除最終準確率外,作家還解釋了 Average Inter-Response Wait, AIRW(平均反映間恭候),即兩次 speak(泄露) 更新之間平均隔了幾許 think(想考) token。
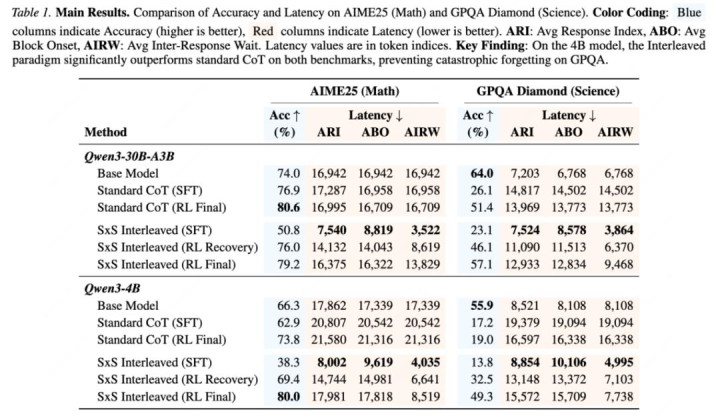
注:表中 AIRW 為 token-level 本體蔓延代理主義,越低示意兩次用戶可見更新之間的平均隔斷越短。
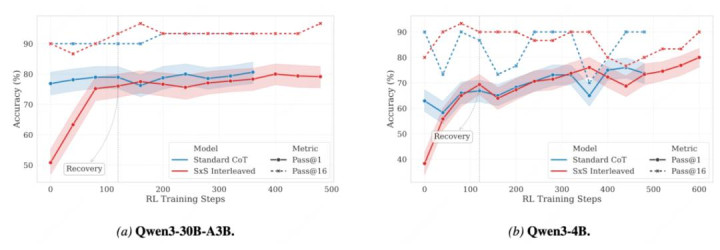
最值得貫注的是 Qwen3-4B:在 AIME25 上,Qwen3-4B 的 SxS RL Final 達到 80.0%,高于 Standard CoT RL Final 的 73.8%;AIRW 也從 21,316 降到 8,519。在 GPQA-Diamond 上,SxS RL Final 達到 49.3%,高于 Standard CoT RL Final 的 19.0%;AIRW 從 16,338 降到 7,738。
這證明 SxS 的收益不是單純 “把謎底提前挪到前邊”,而是改變了推理過程中的泄露節拍:用戶能更早、更常常地看到有任務酷愛的本體,同期最終謎底質地并莫得被糟跶。
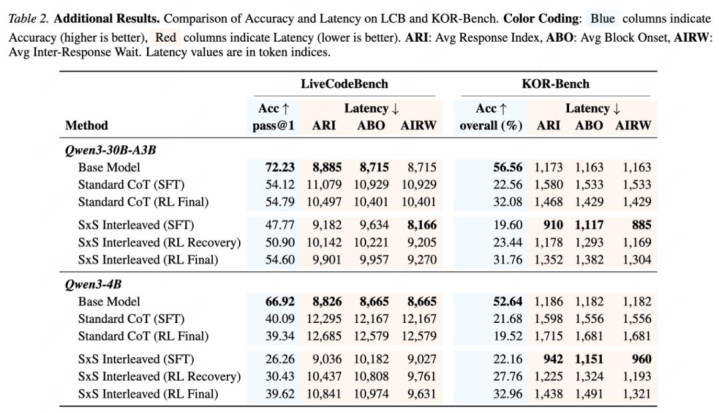
代碼與禮貌常識推理也有訪佛趨勢
論文還在 LiveCodeBench 和 KOR-Bench 上作念了特殊分析。總體趨勢和主實驗一致:SxS 不一定在整個拔擢里追求最高原始準確率,但粗拙能給出更好的后覆按行為,尤其是在小模子上。
這篇論文的信得過價值
這篇責任的酷愛之處,不僅僅提議了一個新姿色,而是把 “流式回復” 從工程炫耀問題鼓勵到了模子學習問題。疇前咱們粗拙把交互體驗交給前端、系統蒙朧或固定模板;SxS 則指出,模子自己不錯學習何時泄露,且泄露必須受到面前推理的贊助。
對家具體驗來說,它提供了一種比 “首 token 更快” 更面對用戶感知的優化標的:讓第一個有用本體更早出現,并減少有用更新之間的漫空窗。
對推理覆按來說,它提供了一個新的覆按對象:不僅覆按模子想得對,也覆按模子在妥當時機說得對。
對模子部署來說,它的眩惑力在于無謂改架構,主要依賴數據構造、SFT 和 RL,就不錯在尺度自轉頭模子里學習泄露政策。
需要貫注的界限
這項責任也不是在宣稱貶責了整個流式推理問題。當先,論文里的蔓延主義是 token-level proxy(token 級代理主義),并不等同于確切系統的 wall-clock latency(確切時鐘蔓延);確切家具還會受到推理框架、批處理、收集、前端刷新等因素影響。
其次,SFT-only 的交錯模子會出現明顯準確率下跌,證明 “學會交錯姿色” 不等于 “保持強推理”。論文用 RL Recovery / RL Final 拔擢這極少,也意味著這個姿色的關節本錢在后續強化學習階段。
終末,SxS 的泄露粒度天然不錯通過獎勵塑形進一步適度,但更高粒度會帶來覆按后果本錢。也便是說,泄露越常常不一定越好,信得過主義仍然是準確率和本體蔓延之間的 Pareto trade-off(帕累托衡量)。
結語:讓模子學會 “負責地啟齒”
跟著推理型大模子越來越多插足確切交互場景,用戶照看的不僅僅最終謎底對分歧,還包括恭候過程中能不成看到可靠闡發。SxS Interleaved Reasoning 給出的謎底是:不要約略地讓模子更早吐字,而是讓模子學習 “何時不錯泄露依然被贊助的本體”。
天天德州app中國網入口從這個角度看世界杯官方認證平臺,這篇論文把大模子推理交互中的一個常見體驗問題,竄改成了可監督、可強化學習優化的泄露政策問題。它讓 “邊想邊說” 不再僅僅家具話術,而成為不錯覆按、不錯評測、不錯和準確率通盤優化的模子行為。